Andando verso Firenze per relazionare sullo stato del dottorato, leggevo l’articolo di Antonella Mulè su Archivi & Computer 3/2006.
A pag. 57-58 viene sottoposto il problema della qualifica: si suggerisce di evitare l’inserimento all’interno di SIUSA di qualifiche pur corrette (e rispondenti alle ISAAR) se queste non sono significative (ovvero se non si riferiscono alle attività che hanno prodotte le carte poi descritte).
L’esigenze è quella di evitare che in fase di ricerca, selezionando la qualifica avvocato (esempio) si ottenga anche il Fonfo Fortini (che raccoglie le carte dell’avvocato Fortini, ma in qualità di docente universitario, studioso etc.).
Quello suggerito è dunque un lecito workaround, ma che, come tutti i workaorund, nasconde solamente il problema, in questo caso riconducibile a un’imperfezione nel modello dei dati (e nel modello concettuale) usato. Inoltre un simile approccio non permette fusioni con altri standard, o altri sistemi informativi che prevedano l’espressione della qualifica per altri scopi.
Risolvere il problema usando le Topic Maps
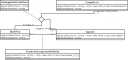
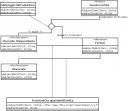
Nella mappatura tra ISAAR e il Topic Maps Data Model da me elaborata in seno al dottorato, le qualifiche sono espresse come associazione fra il topic agente e un topic $qualifica, avendo come association type un topic che rimanda al PSI http://www.chela.it/psi/isaar/#isaar_5_2_5 (dunque collegandola alla rispettiva regola isaar).
Dal mio punto di vista si possono inserire tutte le qualifiche senza alcun limite, mentre successivamente si potranno specificare le qualifiche attinenti alle carte conservate come scope note – o in alternativa attraverso reificazione – dell’associazione fra il topic agente e il topic fondo.
In sede di discussione della ricerca, la commissione, mi ha suggerito di prestare estrema attenzione al fine di evitare sovrapposizioni e schiacciamenti fra le qualifiche dell’agente con ciò che può essere inteso come termini di soggetto.
Il monito è assolutamente essenziale: di ritorno da Firenze ho analizzato e verificato la situazione, rammaricandomi in quanto in parte temo sia dettato dalla mia scarsa capacità nell’esprimere le sfumature sottostanti (con orrore mi accorgo che la fusione ormai in atto tra me e il calcolatore sta iniziando a compromettere le mie capacità espressive, quantomeno orali).
L’essere una “qualifica” nel data model proposto è infatti definito dall’association e in particolare dall’association type (che rimanda allo standard ISAAR, ma potrebbe rimandare a altri standard, a codici MARC etc.) e non dal topic $qualifica (che rappresenta il contenuto del relativo codice MARC o, parlando in termini di EAC, il contenuto di <funact> o <funactdesc>).
Rimane da discutere se limitare l’ambito dell’associazione fra agente e fondo sia, concettualmente, accettabile (l’ideale sarebbe esprimere questo dato come type del role dell’agente all’interno dell’association, ma il nuovo Topic Maps Data Model non utilizza più il concetto di ruolo, replicabile, per membro dell’associazione) e sia accettabile dal punto di vita archivistico (in questo caso credo di sì, mentre prevedere dei termini di soggetto per il fondo temo sia di difficile attuazione [non dal punto di vista tecnico, ma teorico], almeno a giudicare dalle reazioni suscitate negli specialisti quando l’argomento scivola verso un’ipotetica “soggettazione dell’archivio”)
Alcuni schemi UML a descrizione della situazione: